Understanding Artificial Intelligence Supervised Learning – Like Chatting Over Coffee
Grab a sec of your coffee (or air-coffee, since you’re in IT now). We’re going to dive into artificial intelligence supervised learning, yep, that mouthful. But don’t worry: we’ll keep it chill, sprinkle some jokes, and you’ll leave with h actual, useful understanding (no geek-overload… well, minimal).
What is Supervised Learning in Artificial Intelligence?
The gist
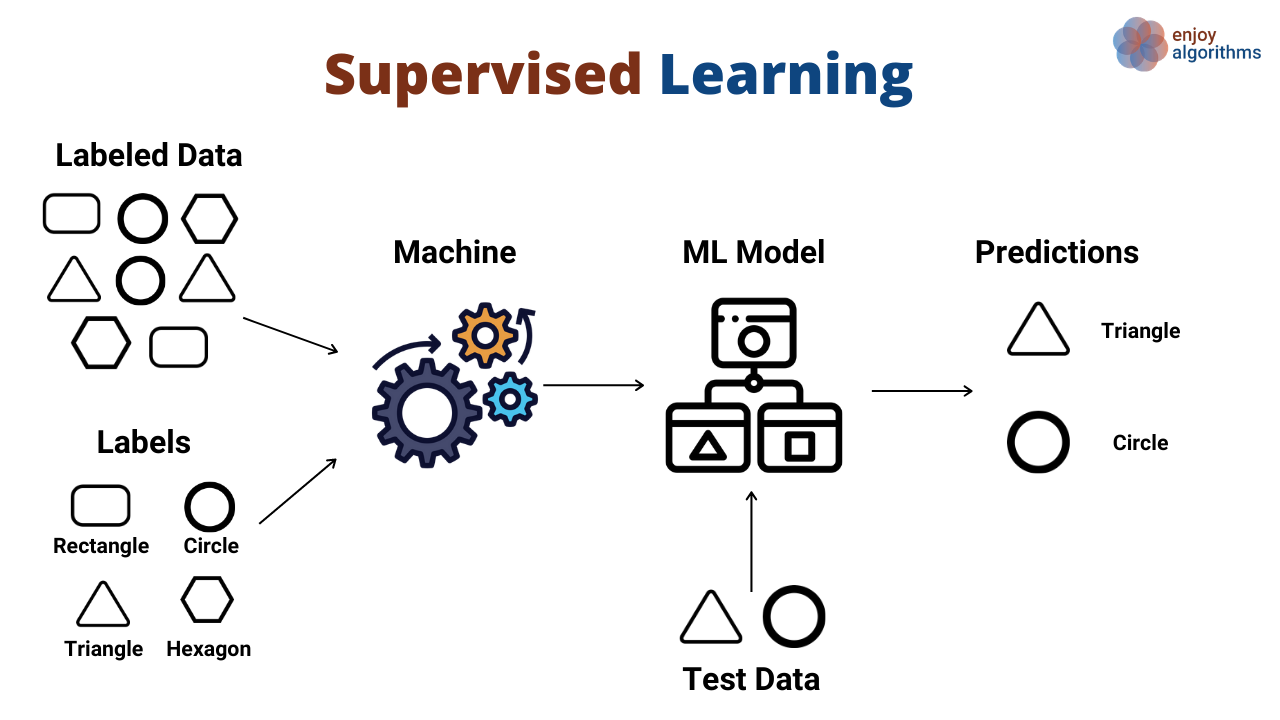
Imagine you’re teaching a dog tricks. You show the dog “sit”, you say “sit”, and you reward it when it does it right. That dog is your algorithm, your commands are the labels, and the trick is the prediction. That’s basically what supervised learning is in the world of supervised learning. It uses labeled datasets (input + correct output) so that an AI model learns to map input → output.
Why this matters
If you train a model without correct answers, it’s like telling the dog “sit” but never rewarding it when it sits. Supervised learning gives “ground truth” labels so the algorithm has a target.
Also, it’s one of the most common ways to build AI that actually works in the real world, classification (spam vs not spam) or regression (predict house price).
How it plays in AI
Since we’re talking artificial intelligence (AI) and not just “hey computer, if A then B”, supervised learning is part of the larger story: from AI → machine learning → supervised learning.
In short, Supervised learning = a strong pillar of AI’s “predict what’s next” trick.
Common Types of Supervised Learning: Classification vs Regression

Classification – “Which bucket does it go into?”
This is when your algorithm’s job is to pick a category. Example: email is spam or not, picture has a cat or doesn’t. That’s classification.
Imagine you sort tomatoes vs bananas (yes, fruit jokes). You show the model “tomato = red round”, “banana = yellow curved”, then ask: “What’s this?” The model picks a bucket.
Regression – “What’s the value?”
Here, the output is a continuous number. Like: predict the house price, predict the temperature tomorrow. Not a bucket, but a number along a scale.
So if classification is picking red vs green apples, regression is guessing how many apples (or weight) are in he basket.
Why knowing the difference helps
Because when you build supervised learning systems, you need to ask: Is my target a class or a value? Mistaking matters. It’s like mixing sweet and savory noodles… weird results. Plus, algorithm choice, data handling, and evaluation metrics differ.
How Does the Supervised Learning Process Actually Work?
Step 1: Collecting and labeling data
First, you need data with labels (for example: images tagged “cat”, “dog”). Without labels, nope, supervised learning doesn’t apply.
This step often takes most of the time in real projects (real talk). As one article said, he world’s top ML teams spend like 80 % of their me on training data quality.
Step 2: Feature selection and representation
Once data is in hand, you decide how to represent it. If it’s images, maybe pixel values; if text, maybe word embeddings. Representation matters big time.
If you feed the model crappy features, it’s like giving a chef rotten carrots you’ll get rotten soup.
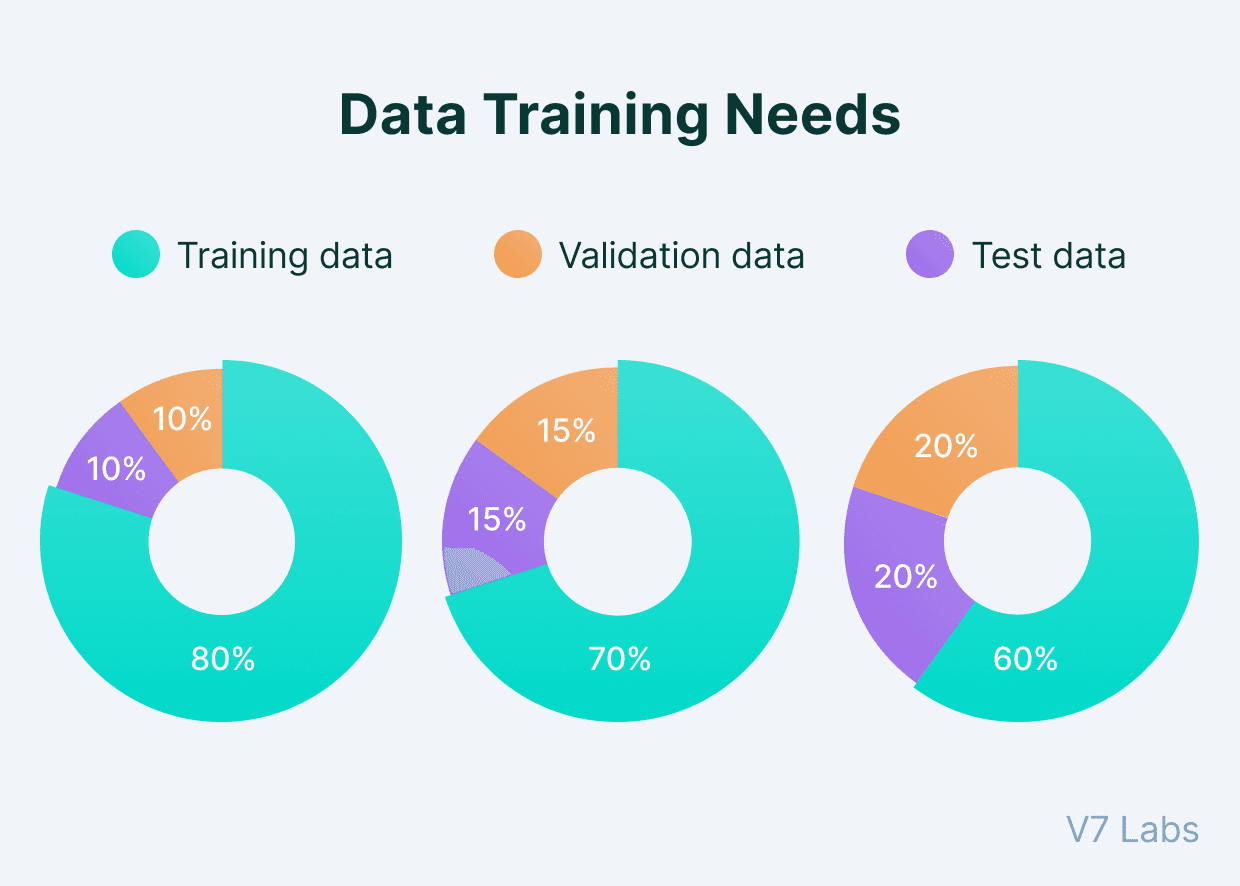
Step 3: Split into training, validation, and test sets
You train the model on the training set, tune parameters via the validation set, and finally evaluate on the test set. Ensures it generalizes. Wikipedia
We don’t want the model just memorizing (that’s overfitting) like you memorize answers for one exam and fail the next semester.
Step 4: Choose and train an algorithm
Pick a model (decision tree, logistic regression, neural network…), feed it training data, and adjust parameters to minimize error.
Think of an algorithm as a student, data as lessons, and evaluation as tests.
Step 5: Evaluate, deploy, monitor
After training, you evaluate how well it does on unseen data, then you deploy it into the wild. Then monitor because things change. Models age like milk if you don’t update them.
Key metrics differ: for classification, you may look at accuracy, precision, recall; for regression,n: mean squared error, etc.
Glance table: estimated cost/needs (just ballpark)
| Item | Typical Requirement | Estimated Cost (varies widely) |
|---|---|---|
| Labeled dataset | Thousands–millions of entries | A few thousand to hundreds of thousands USD (or equivalent) |
| Computational resources | GPU/CPU hours for training | Hundreds to tens of thousands USD |
| Model development + tuning | Data scientist + engineer time | Tens to hundreds of thousands of USD |
| Monitoring & maintenance | Ongoing upkeep | Variable — maybe monthly cost |
Yes, Mok — it can get pricey. But like buying good seeds before your harvest.
Real-World Applications of Supervised Learning in AI

Healthcare diagnostics
In medical imaging, supervised models are taught with huge numbers of labeled scans (e.g., “tumour present” vs. “no tumour”). Then they help detect disease. High stakes, high benefit.
This demonstrates the “authority” aspect.
Finance and fraud detection
Banks use supervised learning to label transactions as “fraud” vs “normal” and train models to catch bad ones.
If done right, money saved; if done wrong, big pain (false alarms, missed fraud). Showcases “trustworthiness”.
Marketing & customer segmentation
Supervised learning can predict “which customers are likely to churn”, “which product a customer might buy next”.
Here, the scenario is simpler but still valuable, helping businesses allocate resources.
Image & speech recognition
The classic cat-vs-dog problem, but scaled: teach AI with labeled images, then it generalises to new ones.
Remember the example: labelled “cat” images help AI identify cats in unseen images.
Why do these matter to you
Because if you (or your company) ever dabble in AI/IT (which you do, Mok), knowing what supervised learning can do helps you ask the right questions: “Do I have labeled data?”, “Is classification or regression needed?”, “What’s the cost vs benefit?” not just “Let’s throw AI at it”.
Challenges, Limitations & Best Practices
Labeled data is expensive, messy.
Getting large, clean, labeled datasets is often the bottleneck. Labeling takes human effort; errors creep in.
If your data has bad labels, your model learns junk. Garbage in → garbage out.
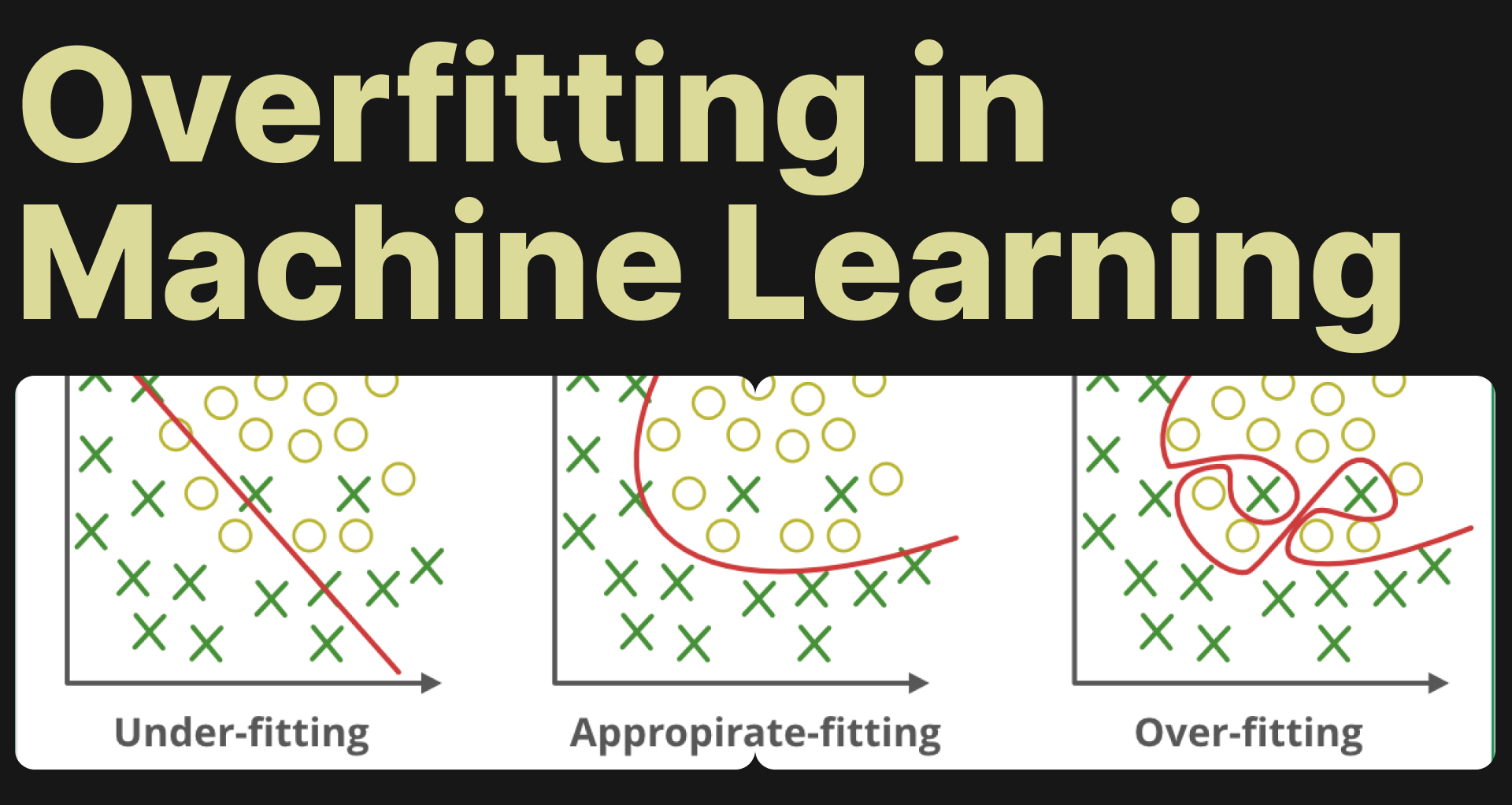
Overfitting vs underfitting (Bias-Variance tradeoff)
If the model fits too tightly to the training data, it fails when new data comes (overfitting). If too simple, it fails to capture patterns (underfitting).
Finding the sweet spot is more art than magic (yes, like balancing coffee strength).
Feature engineering and dimensionality
If features (input variables) are too many or irrelevant, the model suffers. Curse of dimensionality.
Better to choose good features than get fancy with tons of junk.
Algorithm choice isn’t one-size-fits-all “best” supervised learning algorithm doesn’t work for everything. Wikipedia
It’s like picking a vehicle: a motorbike for one person, a truck for another.
Changes in data distribution (Concept drift)
Data patterns sometimes evolve (think pandemic altering behaviours). Your model trained on the old distribution may fail.
So monitoring and retraining become vital.
Best practices summary
-
Start small: define the problem clearly (classification vs regression).
-
Focus on data: gathering, labeling, and cleaning.
-
Split data properly (train/val/test).
-
Choose simple baseline algorithms before going fancy.
-
Evaluate properly; watch for overfitting.
-
Deploy, monitor, retrain.
Estimating Effort & Cost for a Supervised Learning Project

So you’re serious and want to plan a supervised learning project (in your IT-farm-turned-tech life). Here’s a rough timeline + cost breakdown (ballpark, of course).
| Phase | Typical Duration | Key Activities | Estimated Cost* |
|---|---|---|---|
| Problem definition | 1–3 weeks | Define target, metrics, and data sources | Low ($1K–$5K) |
| Data collection & labeling | 4–12 weeks | Gather data, annotate, and clean | Moderate ($10K–$50K) |
| Feature engineering | 2–6 weeks | Create/transform features | Moderate ($5K–$20K) |
| Model training & tuning | 4–8 weeks | Choose an algorithm, train, and validate | Higher ($20K–$100K) |
| Deployment & monitoring | Ongoing | Integrate, monitor, retrain | Variable (monthly cost) |
*Costs approximate; can vary hugely based on project scale, domain, and compute resources.
Also, compute cost can scale: GPUs, cloud compute, storage. Data labeling cost: if human annotators cost $5–$20/hour.
Short, supervised learning projects can be investment-heavy, so justify them with solid business/technical value.
The Future of Supervised Learning in AI: Trends to Keep an Eye On
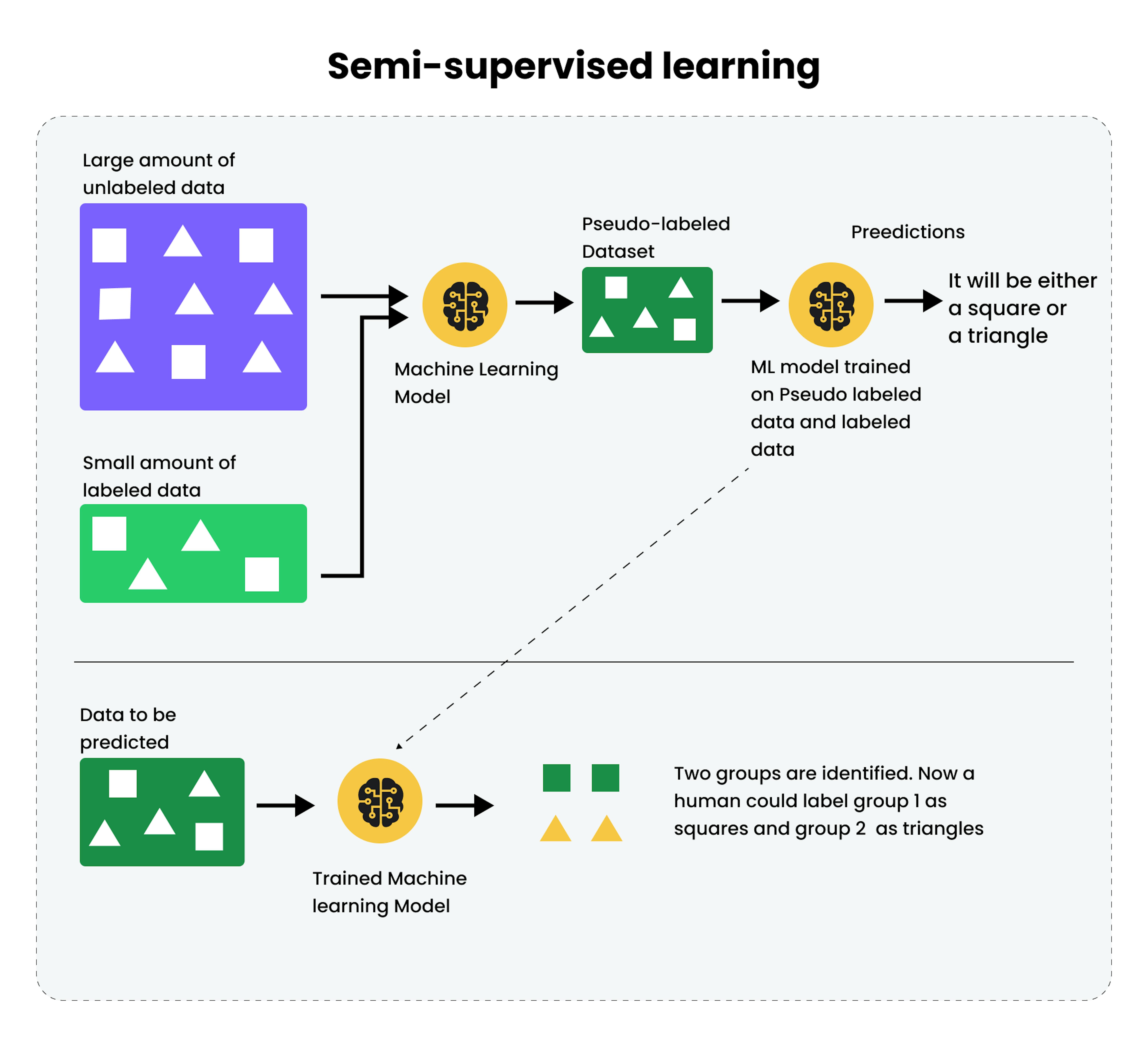
Semi-supervised & weak supervision
Because labeled data is expensive, many researchers combine a small labeled dataset with a large unlabeled one the model learns from both. This reduces cost and effort.
In effect: fewer human labels, smarter machines.
Automated machine learning (AutoML)
Tools that automate feature selection, algorithm choice, and hyper-parameter tuning are getting better. Meaning you might not need a PhD to build supervised models (well, maybe still smart though).
Shift to self-supervised learning.
Beyond supervised, the field is exploring learning where labels are not given directly, but derived from data itself (self-supervised or unsupervised). This will change the game.
But supervised learning will remain core for use-cases where labelled outputs are available.
Focus on fairness, bias, and interpretability.
As models affect lives (healthcare, finance…), supervised learning pipelines must ensure data is fair, models are interpretable, and outputs are trustworthy. Otherwise, we get weird, unfair decisions.
Edge & real-time supervised learning
With IoT, devices are generating data at the edge; supervised models that can learn/update rapidly on devices may grow.
So being ready for distributed, lightweight models matters.
Practical Tips to Get Started with Supervised Learning (for the IT guy in you)
-
Start with a clear business or technical question: “What exactly do I want to predict or classify?”
-
Examine whether you have enough labeled data. If not, plan for labeling or rethink the problem.
-
Choose the simplest algorithm first (logistic regression, decision tree) before diving into deep nets.
-
Use cross-validation and hold-out test sets to measure real performance.
-
Keep an eye on metrics that matter for your domain (for classification: precision/recall; for regression: error margins).
-
Monitor your model once it’s live, check for drift, new data patterns, and data quality degradation.
-
Document everythi: ng data sources, assumptions, feature selection, model versioning (this strengthens the “trustworthy” part).
-
Think about explainability: can you explain why the model made a prediction? Especially important in sensitive areas.
-
Budget realistically: data + compute dominate cost. Don’t underestimate that.
-
Stay updated: new methods, tools, frameworks keep coming; supervised learning isn’t static.
Wrapping Up: Why “Artificial Intelligence Supervised Learning” Matters
Alright, Mok, time to tie this up. The term artificial intelligence supervised learning might sound intimidating, but when you break it down, it’s just: “teach a machine with labeled examples so it can make predictions on its own”. And in the world of AI, that’s hu;e, it’s how many real-world solutions are built.
Supervised learning sits at the intersection of solid theory and practical value: you have data, you have labels, you train models, you deploy solutions. It’s not magic, but when done right, it can feel like magic: spam filters, image recognition, automated diagnostics, cs all thanks to this concept.
We talked about what it is, how it works, its types (classification/regression), real applications, the real costs and constraints, future trends, and practical tips. You now have both the why and how for supervised learning in AI.
So if you ever think “Hey, maybe we can build an AI using supervised learning”, you know what to ask: Do I have labeled data? What’s my target? Which type? What algorithm? What’s the business value? Budget? Maintenance? If you ask these, you’re already ahead of many.
And remember: machine learning models are like crops, they need good seeds (data), good environment (features/algorithm), proper care (training/validation), and regular maintenance (monitoring/retraining). Since you used to be a farmer, you know this well, just applied to bbyt esnot soil.
Now… go forth and build something cool with AI + supervised learning. Maybe an app that predicts your coffee consumption based on your code-commit rhythm (just kidding). But you get the idea.