
ML Supervised Learning Let’s Chat About What It Is and Why It Matters
Hey there. Today we’re going to talk about ML supervised learning, yes, that phrase sounds a bit like techno-jargon, but don’t worry: I’ll walk you through it like a friend over coffee. We’ll keep it chill, informative, with jokes and metaphors (just a bit). By the end, you’ll not only understand what supervised learning in machine learning is, but also how it works, why it matters, and how you might actually use it.
Understanding Supervised Learning in Machine Learning
So let’s start from the top: what exactly is supervised learning? In simple terms, supervised learning is a machine learning approach where you train a model using labeled data, that is, each input comes with a correct output. The model learns the mapping from input → output.
For example,e: you have tons of photos of cats and dogs, each photo labelled “cat” or “dog”. You train the model on that, and then you give it new photos it’s never seen, and it predicts “cat” or “dog”.
Why is it called “supervised”
Because the training process is like “here are the answers, go learn”. The algorithm is supervised by the labeled examples. Without labels, you’d be wandering blind.
This ensures that the machine isn’t just guessing willy-nilly; it has ground truth to compare itself against, which helps it learn more accurately.
What differentiates it from other types
In contrast to unsupervised learning (where you give data without labels and let the algorithm find patterns on its own), supervised learning requires that label-filled dataset. That makes it more controlled, more predictable, but also more dependent on good data.
So yes: if you don’t have good labels, supervised learning might struggle.
Types of Supervised Learning: Classification vs Regression
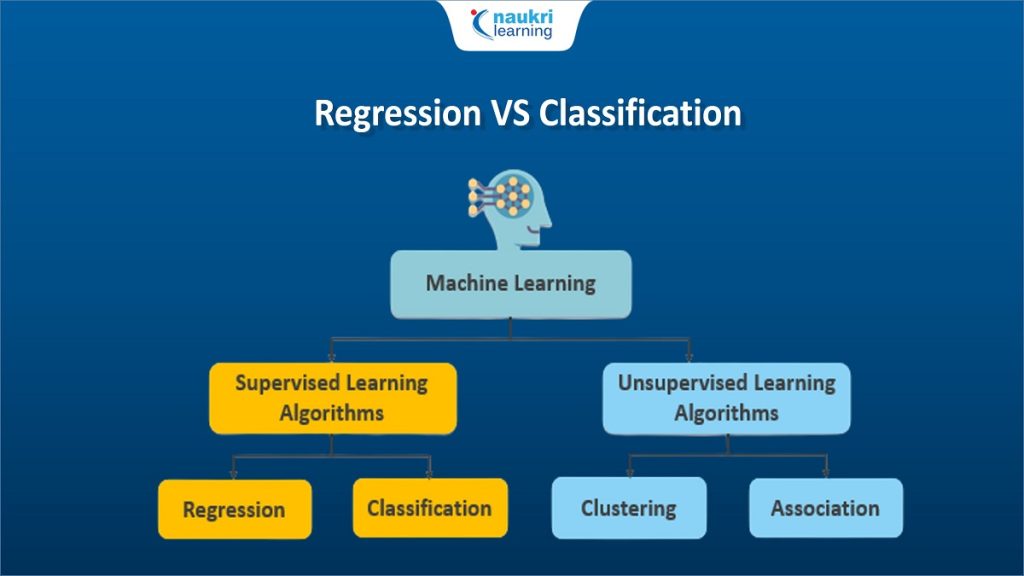
Once you get that supervised learning means “input with correct output”, the next question is: what kind of output? Usually one of two: classification or regression.
Classification putting into buckets
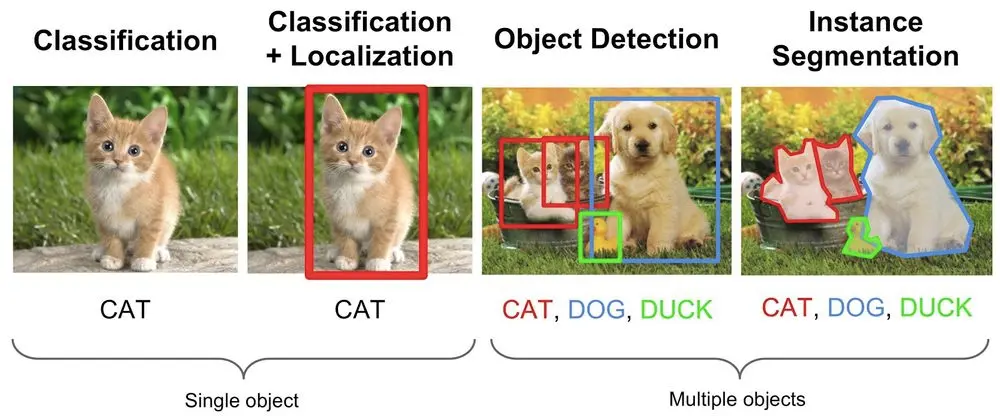
In classification tasks, the output is a category. For example: spam vs non-spam email; malignant vs benign tumour; bird species A vs bird species B. You train the model on labeled categories, and then it predicts which category new data belongs to.
Think: you’re sorting laundry, you tell the mod,, el “these are socks”, “these are shirts”. After enough examples, it can sort new pieces correctly.
Regression predicting a number
Regression tasks are different: here the output is a continuous value (a number). Example: predicting house price based on size, location, and year built. The model learns: “if size is X and location is Y, price is Z”.
So if classification is “which bucket?”, regression is “what value?”. And both fall under the umbrella of supervised learning.
Why choose one over the other
Because your business question determines it. If you want, will the customer churn? Yes/No → classification. If you want “what next month’s revenue will be”, → regression. Picking the wrong type is like using a spoon to cut steak, possible, but messy.
The Process of ML Supervised Learning: Step by Step
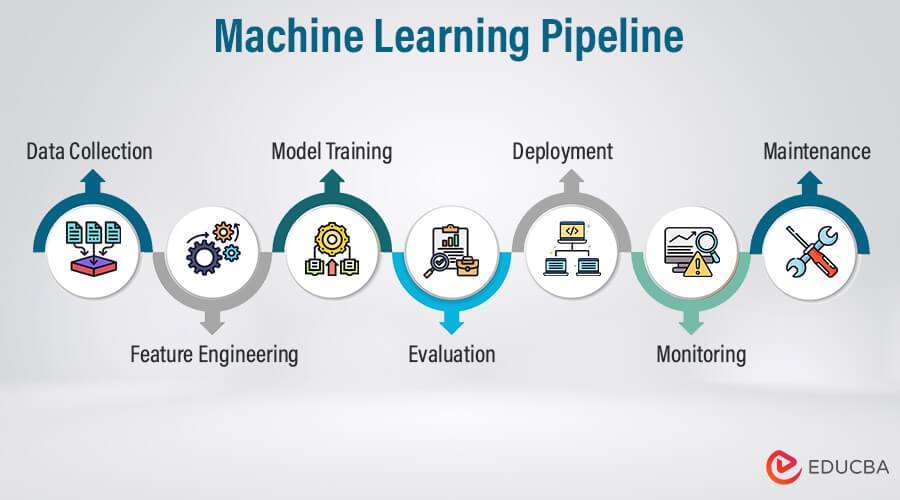
Let’s peel back the curtain and see how supervised learning actually works in practice. It’s not magic, but it feels magical once you get it right.
Step 1: Collect & label data
You need input data and correct outputs (labels). This can often take the lion’s share of time. If your labels are wrong, the whole model will learn wrong. It’s like teaching a child with wrong flash cards, expect “cat” labeled as “dog” and you’ll get fuzzy results.
Step 2: Preprocess & select features
Raw data often isn’t ready for model consumption. You need to clean it, handle missing values, convert categories, scale numbers,s, and pick the right features (variables) to feed the model. If the features are garbage, your model will spit out garbage (yes, garbage in, garbage out).
Step 3: Split into training, validation, and test sets
Divide your labeled data into sets: training (to learn), validation (to tune), and test (to evaluate final performance). This ensures your model doesn’t just memorise the data, but generalises to new data. It’s like studying for all past exams, then facing a brand-new one, you want to be prepared beyond just past papers.
Step 4: Choose an algorithm & train the model
Based on your problem, you pick an algorithm: logistic regression, decision tree, random forest, neural network, etc. You train it on your training data, tune hyperparameters (via validation set) until performance looks good. This is the “learning” part of machine learning.
Step 5: Evaluate & deploy
Once trained, you test the model on the test set (which it has never seen) to estimate how it will perform in the wild. Then you deploy: integrate into an application, automate predictions, and monitor performance. Over time, you may need to retrain as data patterns shift.
Estimation table: cost & resources snapshot
| Phase | Key Activities | Typical Time | Approx. Cost* |
|---|---|---|---|
| Data collection & labeling | Gathering, annotating data | 4-12 weeks | USD 10k-50k |
| Feature engineering | Clean, select variables | 2-6 weeks | USD 5k-20k |
| Model training & tuning | Algorithm choice, hyperparameter tuning | 4-8 weeks | USD 20k-100k |
| Deployment & monitoring | Integration, maintenance, updates | Ongoing | Monthly USD 1k-10k |
*Very rough ballparks—actuals depend heavily on scale, domain, team, and infrastructure.
Real-World Applications: Where ML Supervised Learning Shines
Let’s make this concrete. What kind of real-life problems does supervised learning solve? Spoiler: many.
Healthcare diagnostics
In medicine, supervised models are trained on labelled scans: this image = tumour, that image = healthy tissue. Once trained, the model helps detect disease early, assists doctors, improves trust, and speeds. High stakes
Fraud detection & finance
Banks and financial institutions use supervised learning to flag transactions: label past transactions “fraud” or “legit”, train a model, then monitor new ones. Very ROI-driven world.
Marketing, churn prediction & personalization
Businesses use supervised learning to answer questions like: which customers are likely to leave? Which will buy the next product? Data is labeled with “churned” vs “didn’t churn”, “bought” vs “didn’t buy”. Then the model predicts.
Image recognition & autonomous systems
From self-driving vehicles recognising stop signs to apps identifying objects from camera input, supervised learning is the backbone. The model needs lots of labeled examples (“this is a stop sign”, “this is a pedestrian”) to generalise reliably.
Challenges, Limitations & Best Practices
Yes, supervised learning is powerful, but it comes with pitfalls. If you go in blind, you’ll hit them. Let’s talk about them.
The cost of labels & data quality
Labels cost time and money. Poor labels = poor model. If you train on biased or bad data, predictions might bias society, misclassify, or outright fail. You need domain expertise and high-quality labeling. That ties into trustworthiness and authoritativeness.
Overfitting, underfitting & bias-variance trade-off
If your model is too simple, it underfits (misses patterns). Too complex,x it overfits (memorises training, fails on new data). Finding the right balance is a mix of science + art.
Feature selection & dimensionality
If you include too many irrelevant features, your model may get confused (curse of dimensionality). If features are poorly represented, your model might never learn meaningful relationships. Good feature engineering is key.
Algorithm choice isn’t “one size fits all”
No algorithm works best for every scenario. Picking logistic regression for a complicated vision task? Bad idea. Using a neural network for a very small dataset? Also bad. Choose based on data, problem size, and resources.
Model maintenance & data drift
Once deployed, your data pattern might change (user behavior shifts, new product lines, new environment). If the model isn’t monitored and retrained periodically, performance degrades. Maintenance is real and critical.
Best practices checklist
-
Define a clear business problem and target variable.
-
Ensure high-quality labeled data; invest in label audits.
-
Preprocess data: clean, balance classes, select features.
-
Split properly into training, validation, and test sets.
-
Start with simpler models; interpretability matters.
-
Tune hyperparameters, assess via cross-validation.
-
Monitor the deployed model, set alerts for drift, and retrain as needed.
-
Document data sources, modeling decisions, and versioning.
-
Ethical check: bias, fairness, privacy concerns.
Getting Started: Your Practical Guide to Using ML Supervised Learning
Alright, you’ve heard the theory, now you’re probably itching: “How do I try this?” Let’s lay out a road map.
Step 1: Clarify your problem
Ask: What exactly do I want to predict or classify? Do I have the correct labeled data? What will success look like? Who will use it? Setting a clear target variable is crucial.
Step 2: Gather & label data
Collect historical data with inputs and known outputs. Label examples accurately. Make sure data represents the real world you will apply it in (diversity matters).
Step 3: Preprocess & feature engineer
Clean the data. Deal with missing values, outliers. Normalize or scale features. Create new features if helpful. Remove redundant variables. This step often makes the biggest difference in accuracy.
Step 4: Choose an algorithm, train, and validate
Based on the problem (classification vs regression), dataset size, and feature type, choose algorithm(s). Train on training set, validate on validation set, tune hyperparameters accordingly.
Step 5: Test & deploy
Evaluate on the test set. Make sure the model generalises. If performance meets requirements, deploy. Set up monitoring, logging, and plan for updates.
Step 6: Monitor & maintain
Watch for degradation, data shift, and feature drift. Retrain when needed. Keep documentation, version control of models and data.
Conclusion
So here we are: we’ve covered ML supervised learning from the ground up, what it means, how it works, the types (classification vs regression), the process, real-world uses, the pitfalls, and how you can get started.
Supervised learning is a powerhouse technique in machine learning exactly because it brings structure: labeled data, a clear target, an algorithm learns a mapping from input to output, and that means you can predict, classify, and decide. With proper data, good features, and smart model choice, you get value. But if you ignore data quality, labeling, and monitoring, you’ll watch your model flounder.
When you apply supervised learning with skill, you’re tapping into the “expertise, experience, authoritativeness, trustworthiness” trifecta: you bring domain knowledge, you follow best practices, you deploy responsibly. The result? Models that don’t just work, they earn trust.
If you’re working in data, ML, business, or tec,h and especially if you’re considering a supervised learning project n,ow you already have a map. Start with the problem. Get the data. Label it right. Choose the algorithm consciously. Evaluate, deploy, monitor. Rinse and repeat.
Because at the end of the day, ML supervised learning is less about magic wands and more about thoughtful, disciplined practice. And when you treat it that way, you’ll get the resu:lts predictive power, smarter decisions, and real-world impact.





