
Non Supervised Machine Learning think of it as the “let’s explore and discover” mode of ML
Alright, pull up a chair, grab your favourite drink, and let’s chat about supervised machine learning. I promise: we’ll keep this conversational, a little funny, and lots of “aha” moments. No heavy math walls, just a smooth ride into how machines can learn even when we don’t give them the answers up front.
In the data world, supervised learning is like handing a student a workbook “Here are questions, here are answers, learn to map these.” But non-supervised learning? That’s like giving someone a mysterious box of puzzle pieces with no picture, and saying, “Go figure what’s inside.” It demands more curiosity, more exploration, and yes, more domain savvy. But it’s also extremely powerful. Let’s unpack how.
What non-supervised machine learning?
At its core, non-supervised machine learning (sometimes “unsupervised learning”) is where we feed an algorithm input data only, without explicitly labelled outputs, and the algorithm is tasked with finding structure, patterns, or representations all by itself. Think of it like a detective exploring raw clues, rather than being told “this clue means that”.
Why this matters

In many real-world scenarios, we simply don’t have nicely labelled data. Maybe someone forgot to tag 10 million customer records. Maybe the data is new and no one knows how to label it yet. In that case, non-supervised ML comes in, enabling the discovery of hidden patterns, grouping similar items, detecting anomalies, and reducing dimensions. In other words, you still learn something useful when you don’t know exactly what you’re after.
Key definitions
Tag image: “definition unsupervised learning overview”
-
Input data: raw features without “correct answer” tags.
-
Goal: discover structure, clusters, hidden representations, and anomalies.
-
Typical techniques: clustering (group similar), dimensionality reduction (compress), association (find co-occurrence), anomaly detection.
-
Benefit: Less upfront labelling, more discovery.
-
Trade-off: Often harder to evaluate, interpret, and requires more domain insight.
Common techniques in unsupervised machine learning
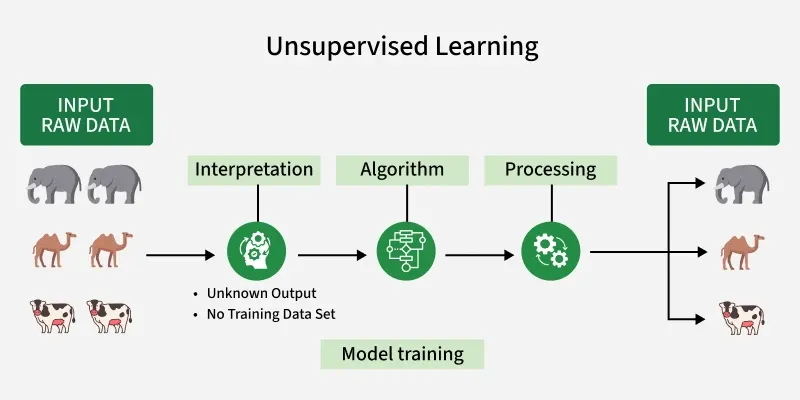
Let’s take a stroll through the main tactics you’ll see in non-supervised ML. The tools you’d pull out of your data-science belt when you don’t have labels.
Clustering grouping like with like
Clustering algorithms try to find groups (clusters) in data such that items in the same group are more similar to each other than to items in other groups. For example, segmenting website visitors into behaviour groups without having predefined labels like “shopper” or “browser”.
How it works in practice: you pick a clustering method (K-Means, hierarchical, DBSCAN), choose a distance or similarity measure, and maybe determine the number of clusters (or let the algorithm decide). Then interpret the groups: “Oh, here’s group A that spends a lot but buys rarely; group B that visits once and leaves fast.”
Why it’s useful: Helps in segmentation, marketing, and exploratory analysis.
Dimensionality Reduction making data simpler
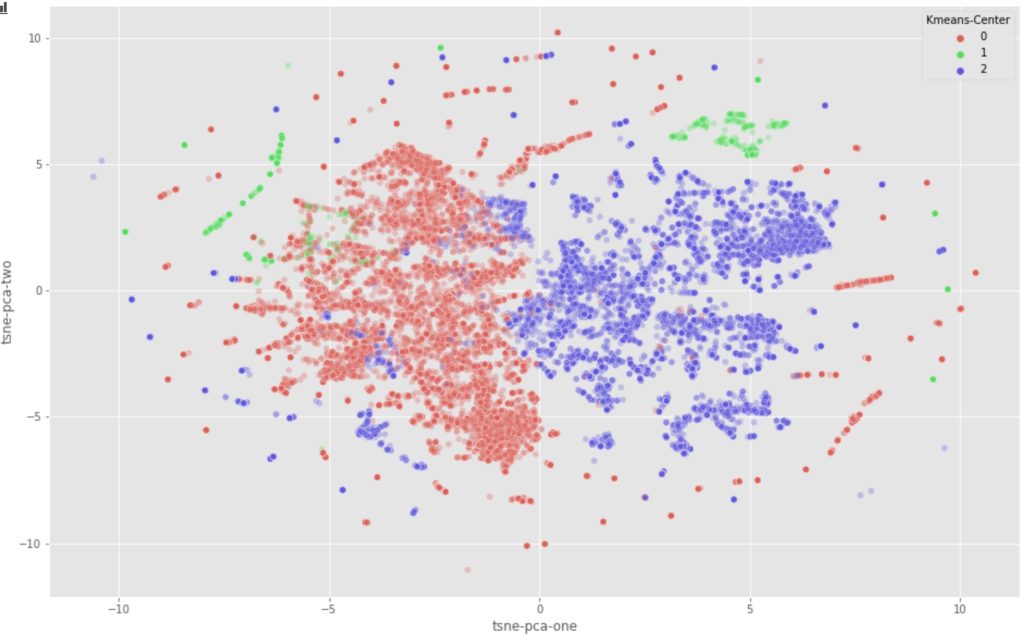
When you have a dataset with many features (dimensions), dimensionality-reduction techniques help you compress data into fewer dimensions while preserving the “most important” structure. Methods like PCA, t-SNE, and UMAP fall here.
Use case: maybe you have 100 sensor readings per machine; dimensionality reduction helps you summarise into 2–3 variables you can visualise or even feed into downstream models.
Anomaly / Outlier Detection: finding the odd ones
Sometimes your goal is less about groups and more about “what doesn’t belong?” With unlabeled data, anomaly detection algorithms (Isolation Forest, LOF, etc) help find unusual items. For instance: fraud detection, machine fault detection, and network intrusions.
Association Rules & Feature Learning: Discovering hidden relationships..
Another technique: exploring data to discover rules like “people who bought X also bought Y” o n,e by association rule mining (Apriori, FP-Growth). Useful in retail, recommendation engines. Also, unsupervised feature learning (autoencoders) to extract “latent” features without labels.
Workflow of an unsupervised machine learning project
Now, how do you actually run a non-supervised ML project? While there’s overlap with supervised workflows, some steps change significantly. Let’s stroll through it.
Step 1: Understand & prepare your data
Even before you pick algorithms, get familiar with your data. How many records? How many features? Are there missing values? Are attributes meaningful? Because without labels, the data’s story is what you’ll build on. Clean it: handle missing, standardise, maybe categorical to numeric, scale features. Feature engineering still matters big time.
Step 2: Choose your objective
Ask: What am I trying to achieve? Maybe: segment users, detect anomalies, reduce features. Defining the objective helps you pick a technique and evaluate later. Even though unsupervised is “let the algorithm discover”, you still need some goal.
Step 3: Select technique & model
Based on the objective, pick a method: clustering? Dimensionality reduction? Anomaly detection? Then choose the algorithm accordingly. Also, decide how to scale, normalise, an choose similarity/distance metrics.
Step 4: Run the model & interpret results
This part separates non-supervised from supervised: interpreting the results often requires domain expertise. After the algorithm runs, you look at clusters, visualise them, label clusters manually, and understand meanings. For anomaly detection, you inspect flagged items. For dimensionality reductionn you visualise e compress the space.
Step 5: Deploy or use insights
Once you’ve gleaned insight, e.g., identified segments, anomalies, latent features, you integrate them: maybe feeding into marketing campaigns, alert systems, oor usingcompressed features into a supervised model next. Monitoring still matters: patterns shift, clusters may change meaning.
Resource/Cost Estimation Table
| Phase | Key Activities | Typical Duration | Approx Cost* |
|---|---|---|---|
| Data prep & exploration | Cleaning, feature creation | 2-8 weeks | USD 5k-25k |
| Model & technique selection | Running clustering/dim reduction experiments | 1-4 weeks | USD 2k-10k |
| Interpretation & integration | Visualisation, domain expert labelling, integration | 2-6 weeks | USD 5k-15k |
| Deployment & monitoring | Use in production, monitor drift | Ongoing | The monthly cost varies |
*These are very rough ballparks – actual cost depends on data size, team, and compute.
Real-world use cases of non-supervised machine learning
Let’s zoom out into the real world and see where non-supervised ML gets used. Not just theory, actual impact.
Customer segmentation & behavioural clustering
Businesses with lots of customer data but not enough labels often ask: “What types of customers do we have?” Unsupervised clustering helps segment them: based on purchase history, browsing patterns, demographics, without having predefined buckets. Then marketing strategiesare tailoredr to each cluster.
Anomaly detection in operations & security
In manufacturing, you might have sensor data streaming. You don’t know exactly which faults will occur, and labelling every fault is impractical. An unsupervised model learns “normal behaviour” and flags deviations for inspection. Similarly ,in network security, unusual traffic patterns.
Feature extraction & preprocessing for downstream models
Sometimes, unsupervised is a pre-step to supervised. Example: you reduce high-dimensional data into fewer features using autoencoders (unsupervised). Then you feed those features into a supervised model for prediction. This improves performance, reduces complexity.
Recommendation & association mining
In retail e-commerc,e you might not havlabelleded “these two items always bought together” data. Using association rule mining (unsupervis,ed) you find “people who bought X also bought Y” patterns. These become recommendations.
Challenges, limitations & best practices non-supervisedised machine learning
As with any tool, non-supervised ML has its shine and its shadows. If you go in unprepared, you’ll hit snags. Let’s be honest about what they are and how to avoid them.
Harder evaluation and interpretation
Without labels, how do you know if you found good clusters or not? Metrics exist (silhouette score, Davies-Bouldin), but often you need domain experts to interpret results. If you skip that, you may end up with clusters that look “cool” but are meaningless.
Risk of finding meaningless patterns
Just because you can find clusters doesn’t mean they are useful. The model might group data by something trivial (e.g., data entry timestamp) rather than business-relevant traits. That’s why domain context matte;rs your experience and authoritativeness count.
Data quality still matters (even more so)
Although you don’t need labelled data, you still need good input data: consistent features, correct scales,and cleaned entries. If data is messy, the model may group noise, outliers or artefacts instead of meaningful patterns.
Scalability & resource requirement
Large datasets unlabeled? Great but unsupervised methods might require substantial computing (especially for dimensionality reduction or large clustering). Planning for resources matters.
Best practices to stay on track
Tag image: “best practices unsupervised ML checklist”
-
Start with exploratory data analysis (EDA,) know your data well.
-
Engage domain experts early so clusters or patterns make business sense.
-
Visualise results: scatter plots, heatmaps, dendrograms to see what the algorithm found.
-
Don’t over-tune clusters: keep simplicity in mind.
-
Use unsupervised as a stepping stone: for segmentation, or for feature creation for supervised tasks.
-
Monitor over time: patterns shift, clusters may evolve.
-
Document everything: data sources, parameter settings, cluster interpretations.
Getting started with non-supervised machine learni:ng your action plan
You’re ready to jump in? Awesome. Here’s your friendly roadmap for a first non-supervised machine learning project.
Define the exploratory goal.
Ask yourself: What do I want to discover? Maybe: “What customer groups exist?”, “Which machines are behaving unusually?”, “Can I reduce hundreds of features into something smaller for later?” Having a clear goal guides technique and makes results actionable.
Get and prep your data.
Gather the data you have (no need for labels). Clean it: check for missing values, duplicates, consistent formatting, scale numeric features, convert categoricals as needed. Because quality inputs lead to meaningful clusters.
Choose your technique and run experiment.s
Based on goal: if segmentation → clustering; if feature reduction → PCA/t-SNE; if anomalies → isolation fore,st etc. Run experiments, try differenumbersber of clusters or reduction dimensions, visualise resuland ts, pick what looks meaningful.
Interpret outcomes & integrate insights.
Review what clusters mean, label them with human-friendly names (e.g., “High-Value Browsers”, “Frequent Shoppers”), and hook them into business action (marketing campaign). If you reduced features, maybe feed them into a supervised model later.
Monitor, refine & scal.e
Deploy insights, watch for driftand , revise parameters or techniques if data changes. As your system evolves, include this maintenance in your workflow.
Conclusion
Whew, that’s our deep dive into the world ofnon-supervisedd machine learning. We explored what it is, why it matters, looked at the key techniques (clustering, dimensionality reduction, anomaly detection, association rules), walked through a real-world style workflow, covered use cases, discussed challenges and best practices, and mapped out how you can get started with it.
The beauty of non-supervised machine learning lies in discovery: when you don’t know exactly what you’re looking for, but you know you have lots of data and you want insights. It demands curiosity, interplay with domain expertise, and a readiness to interpret results rather than rely on a neat “label → outcome” story. In doing so, it unleashes styles of intelligence that supervised learning can’t always cover.
Of course, it’s not magic. Without labels, you lose some of the clear measurement, and you may spend more time interpreting than just predicting. But the reward is big: new segments, hidden patterns, anomalies spotted early, features uncovered that you never thought to ask for. That’s pure exploration combined with machine smarts.
In practice, the strongest data initiatives often use a mix: use unsupervised to explore and structure the data, then bring in supervised to build predictive models. That gives you the full stack: discover, then deploy.
So if you’ve got a heap of unlabeled data, or you’re asking “What is going on in our data that we haven’t named yet?”, then non-supervised machine learning might just be the tool for you. Be playful, be curious, rely on your domain knowledge, and yes, expect some surprises. Because when the algorithm starts grouping things you never expected, that’s when the real insight kicks in.
Here’s to your next data adventure: let the machine do the exploring, you interpret it, act on it, and turn patterns into value.






