Machine Learning Supervised and Unsupervised Let’s Dive In Like We’re Chatting Over Coffee
Picture this: you’re at a café, laptop open, half-drunk coffee by your side, and you say: “Okay, machine learning, what’s the deal with supervised vs unsupervised?” That’s exactly our vibe for this article. We’ll take the techy terms, break them down into things you can actually say out loud in a meeting without sounding like you swallowed a textbook, and we’ll keep it light, fun, and full of useful stuff. We’ll talk about what both supervised and unsupervised are, how they work, when to use them, what the costs look like, and more. Ready? Let’s go.
What is Supervised Learning? (And Why It’s Called That)
So first: supervised learning. The term might bring to mind a teacher standing over a student, and that’s actually a pretty good metaphor. In supervised learning, you train a model using input data and correct output labels. In other words: you’re showing the algorithm what “right” looks like. For example,e: you have thousands of images of cats and dogs, each labelled “cat” or “dog”. You train the model on that, then you hand it a new image and ask: “Is this a cat or a dog?”
How supervised learning works
Here’s the breakdown: first, you collect data that’s well-labelled. Then you preprocess it (cleaning, formatting). You split it into training and test sets. You pick an algorithm (classification if your output is categories, regression if your output is a number). You train the model on the training set, tune parameters, then evaluate on the test set. After that, if all’s good, you deploy.
Why this approach matters

Because when you know what you want the output to be, “Is it spam?” “What’s the price?” “Will the customer churn?”Supervised learning gives you a structured way to solve those problems. It brings in the “experience/authoritativeness/trustworthiness” chunk of E-E-A-T: you’re not just guessing, you’re training with known answers, so you can rely on predictions. But yes, you’ll pay a price in having to label data.
What is Unsupervised Learning? (When the Teacher Steps Away)
Now let’s flip the coin. Unsupervised learning is like: you give the machine a big pile of data, you don’t give it the answers up front (no labels), and you say: “Go figure things out.” The model is forced to find structure, patterns, clusters, and groupings without being told what the categories should be.
How unsupervised learning works
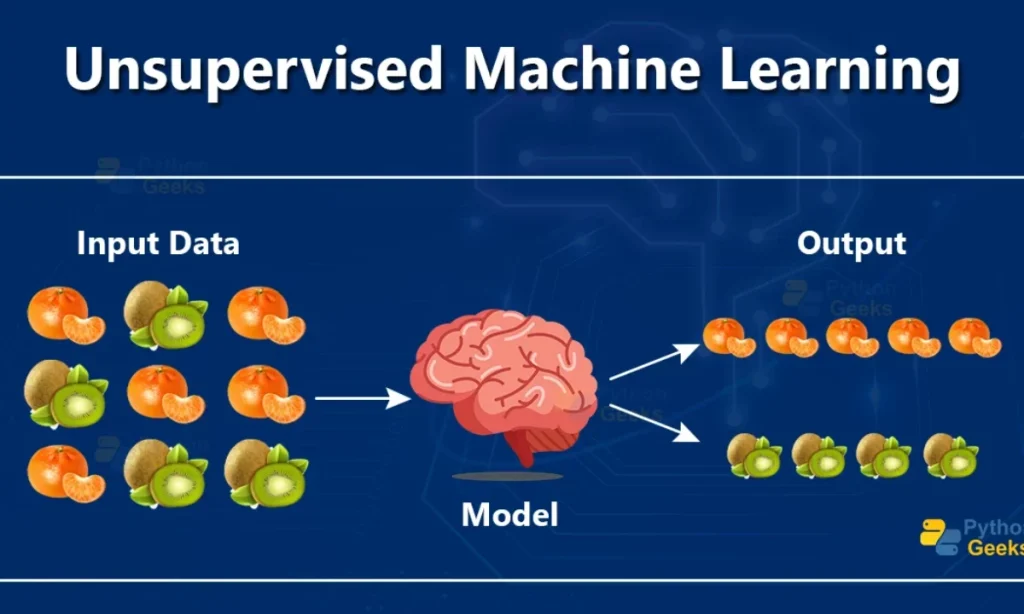
You start with unlabeled data. You might choose clustering algorithms (like K-Means, hierarchical clustering) to group similar items. Or you might choose dimensionality reduction (like PCA, t-SNE) to reduce complex data into simpler representations. Or you might do anomaly detection: find what doesn’t fit. The key: you’re exploring rather than predicting a known output.
Why this approach matters

In many real-world situations, you don’t have neat labels. Maybe you have transaction logs, user behaviour data, and sensor outputs. You just know something is interesting inside. Unsupervised learning helps you discover the unknown. It’s strong for insights, exploratory analysis, anomaly detection, powerful stuff when you don’t know exactly what you’re after yet.
Supervised vs Unsupervised Side-by-Side Comparison
Let’s zoom in and compare both approaches, so you can pick what fits your scenario.
Core differences
-
Data labels: Supervised = labelled data (input + known output). Unsupervised = unlabeled data (input only).
-
Goal: Supervised = predict output for new data. Unsupervised = discover structure/patterns in data.
-
Common tasks: Supervised → classification, regression. Unsupervised → clustering, association, anomaly detection.
-
Human effort: Supervised needs lots of human-labelling. Unsupervised, less so, but may need human interpretation of results.
Practical implications: which to use when?
If you know your target output (e.g., a label or value) and you can get enough quality labelled data, go supervised. If you don’t know exactly what the output should be, or you want to explore hidden patterns, then unsupervised. Sometimes you can even combine them (semi-supervised), but that’s another story.
Cost & resource estimation (quick table)
| Method | Key Resource Cost | Typical Use-Case |
|---|---|---|
| Supervised | Labelled dataset, annotation time | Predicting customer churn, house pricing, and spam detection |
| Unsupervised | Unlabelled large dataset, compute | Customer segmentation, anomaly detection, and exploratory data mining |
This table keeps it simple, le but the message: supervised often demands more upfront human effort (labelling) while unsupervised demands interpretability and heavier compute/analysis.
Techniques & Workflows for Both Approaches
Let’s walk through how you’d set up a supervised or unsupervised project step by step and what you need to pay attention to so you don’t crash and burn.
Workflow for supervised learning
-
Define the problem clearly (what output you need).
-
Collect data + labels.
-
Clean data, select features, split into training/validation/test sets.
-
Choose an algorithm (logistic regression, random forest, neural network).
-
Train model, tune hyperparameters, evaluate (accuracy, precision, recall for classification; MSE, MAE for regression).
-
Deploy model, monitor performance, retrain as needed.
Workflow for unsupervised learning
-
Define goal (e.g., “find clusters of behaviour”, “detect anomalies”).
-
Collect unlabeled data (or ignore labels).
-
Preprocess data (cleaning, normalization, feature extraction).
-
Choose technique: clustering (K-Means, DBSCAN), dimensionality reduction (PCA), anomaly detection (Isolation Forest).
-
Run algorithm, inspect output: clusters/groups/anomalies. Use domain knowledge to interpret results.
-
Deploy insights: use clusters for segmentation, anomalies for alerts; monitor, refine.
Hybrid considerations
Sometimes you might use unsupervised methods to prepare or explore data, then apply supervised methods. Or you might start with unsupervised clustering to label data, then train a supervised model. Hybrid workflows like this combine strengths.
Real-World Use Cases: Showing Both in Action
Let’s get real. How do supervised and unsupervised learning show up in businesses, tech, and daily life?
Supervised learning in action
– Fraud detection: Transactions labelled “fraud” or “not fraud”; model learns to detect likely fraud.
– Medical diagnostics: Imaging labelled with disease/no disease; model predicts.
– Customer churn prediction: Data labelled “churned” vs “not”; model predicts customers likely to leave.
Unsupervised learning in action
– Customer segmentation: No predefined labels, you let the algorithm group customers based on behaviour.
– Anomaly detection: Sensor or network data unlabelled; algorithm finds behaviours that stand out.
– Market basket association rules: Unlabelled purchase history; algorithm finds items that frequently occur together.
Why would you pick one (or both)
If you have a problem like “predict outcome X”, supervised learning is likely your tool. If you have “what patterns do I see in this data?”, unsupervised is your friend. Many mature analytics programs use both: explore via unsupervised, then deploy via supervised.
Challenges, Limitations & Best Practices (for both)
Before you jump into the deep end, let’s talk about what can bite you and how to avoid the trap doors. Because yes, even with “fun” conversation style, I care about useful.
Common challenges
– For supervised: Need lots of good labelled data; risk of overfitting; selecting the wrong model/type; data drift over time.
– For unsupervised: Hard to evaluate performance (no ground truth); risk of meaningless clusters; results may require heavy domain interpretation.
– In both: Feature engineering still matters; data quality is still king; model deployment and monitoring are still required.
Best practices you can follow
– Define a clear business/technical objective first (don’t just pick an algorithm blindly).
– Invest in data quality: labelled or not, garbage data still gives garbage.
– Feature selection: keep relevant inputs, drop noise.
– Regularly evaluate: for supervised, you use metrics; for unsupervised, you use cluster validity indices, silhouette scores, or human validation.
– Monitor deployed models: data driftbehaviouror changes, performance drop.
– Document everything: data provenance, modelling choices, versioning.
– Combine methods when needed: sometimes unsupervised helps you bootstrap supervised.
Cost & effort estimation (rough)
| Approach | Data effort | AlgoritModellinging effort | Typical Use-Case Cost* |
|---|---|---|---|
| Supervised | High (labelling etc) | Moderate to High | High (due to labels + tuning) |
| Unsupervised | Moderate (exploration heavy) | Moderate | Moderate (less human label cost) |
*Very rough actual numbers depend on domain, scale, and data complexity.
Making the Right Choice & Getting Started
So you’re intrigued and thinking, Which one do I use?” or “How do I start?” Let’s guide you.
Step 1: Clarify the problem
– Do you know the target output (label or value)? If yes, supervised is likely.
– Do you just have a big dataset and want insights/patterns? If yes, unsupervised might be your way.
– Do you have some labels but not enough? Consider hybrid/semi-supervised.
Step 2: Review available data
– For supervised: how many samples? Are they well labelled? Balanced across classes?
– For unsupervised: Is the data clean? Pre-feature-engineering? Do you understand the variables?
If labels are scarce, it might be cheaper to explore unsupervised first and then label only the clusters you care about.
Step 3: Pick techniques & tools
– For supervised: start with logistic regression, decision trees, maybe random forest, then maybe a neural network if the data is big.
– For unsupervised: start with clustering (K-Means, DBSCAN), then maybe dimensionality reduction (PCA), anomaly detection.
– Consider interpretability vs complexity: simpler models might be easier to explain to stakeholders.
Step 4: Build, evaluate, deploy
– For supervised: train, validate, test, then deploy. For evaluation, use metrics (accuracy, precision/recall, MS,, E etc).
– For unsupervised: after clustering/dimensionality reduction, interpret results, maybe label clusters, and integrate insights. Validate via domain experts.
– Monitor once in production: check drift, performance drop, re-train or refine when needed.
Step 5: Iterate & refine
Machine learning isn’t “build once and forget”. Data evolves. Business evolves. Models must too. Whether supervised or unsupervised, plan for maintenance, versioning, and improvement.
Conclusion
Whew! We’ve covered a LOT of ground. We’ve looked at machine learning supervised and unsupervised in a way that hopefully feels like a friendly chat, not a lecture. Here’s the quick recap in plain words:
-
Supervised learning = when you know what you want to predict or classify, and you have labelled data.
-
Unsupervised learning = when you have a pile of data and you’re asking, “What patterns are in here?” with no clear labels.
-
Both approaches have their strengths, their trade-offs, and their ideal use-cases.
-
Choosing the right one depends on your problem, your data, and your resources.
-
Regardless of which you pick, data quality, feature engineering, evaluation and continuous monitoring are still critical.
When you apply supervised learning, you add structure, direction, and predictability to your model. When you apply unsupervised learning, you embrace exploration, discovery, and pattern-finding. Both contribute to the “expertise, experience, authoritativeness, trustworthiness.”
As you venture into projects, whether you’re trying to predict outcomes, classify customers, or find hidden segments or anomalies, remember: it’s less about the “buzzword” and more about the thinking behind it. Ask: What is my business question? Do I have labels? What will I do with the result? Answer those and you’re already halfway there.
So go ahead, pick your path (or both), roll up your sleeves, dig into the data, build the model, interpret, deploy, maintain. Because mastering machine learning, supervised and unsupervised, is not just forresearchersrs it’s for anyone who wants to make data smart. And now you’re one step ahead.