Understanding Non Supervised Machine Learning Let’s Dive In
Imagine you throw a party and there’s no playlist. Guests roam around, cluster into groups, chat, dance, and bounce. No DJ telling them what to do. That’s kind of like what non-supervised machine learning does: data gets tossed in, no clear labels, and machines figure out patterns by themselves.
In this article, we’ll walk through non-supervised learning is, why it’s useful, how it works under the hood (without making your brain fry), where it’s used in the wild, and what you should watch out for if you want to ride this tech wave. Let’s keep it chill, informative, with a bit of humor and plenty of relatable metaphors.
What is Non-Supervised Machine Learning?
So what exactly is non-supervised machine learning (also called unsupervised learning)? In simple terms, it’s the branch of machine learning where your algorithm gets input data only (no output labels), and it’s tasked with finding structure, patterns, or representation within that data.
Why this matters in AI
No labels? No problem. In many real-world situations, you don’t have neat “this is cat” / “this is dog” labels. You just have a ton of data. Non-supervised methods let you make sense of that chaotic pile. It’s part of the you rely on techniques that are known (authoritativeness) and you apply them responsibly (trustworthiness).
How it differs from supervised learning
In supervised learning, you have input and a known correct output. You’re showing the machine “this leads to that”. Inon-supervised, you don’t provide “that” machine figures out “this probably goes with that”, “these things look similar”, “this is an odd one out”. It’s like giving a bunch of puzzle pieces with no final picture and letting the model assemble clusters or insights.
Common Techniques in Non-Supervised Learning
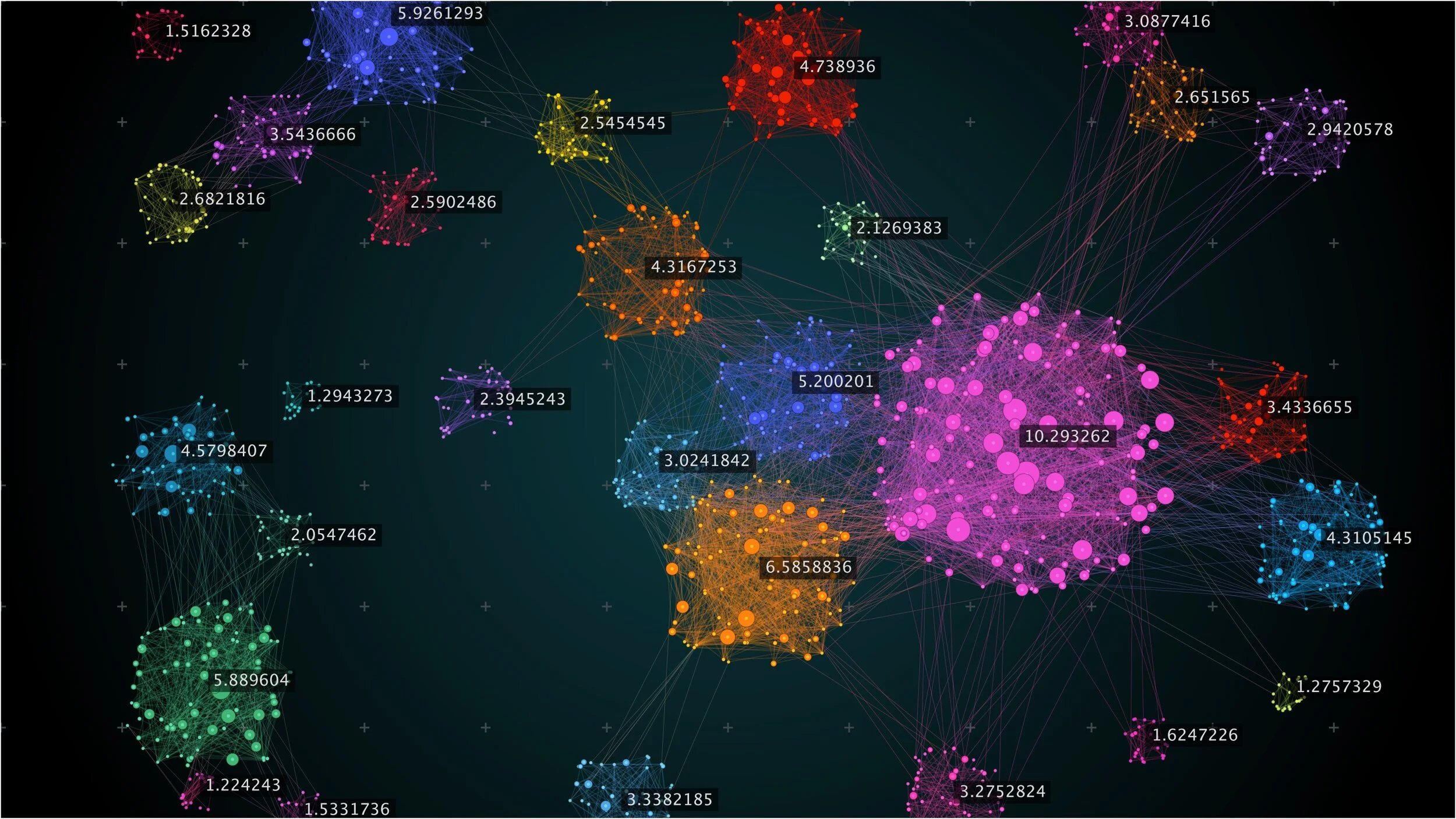
Let’s get into the mechanics. What tricks do machines use when they’re left on their own? We’ll explore a few main categories.
Clusterin: grouping things together
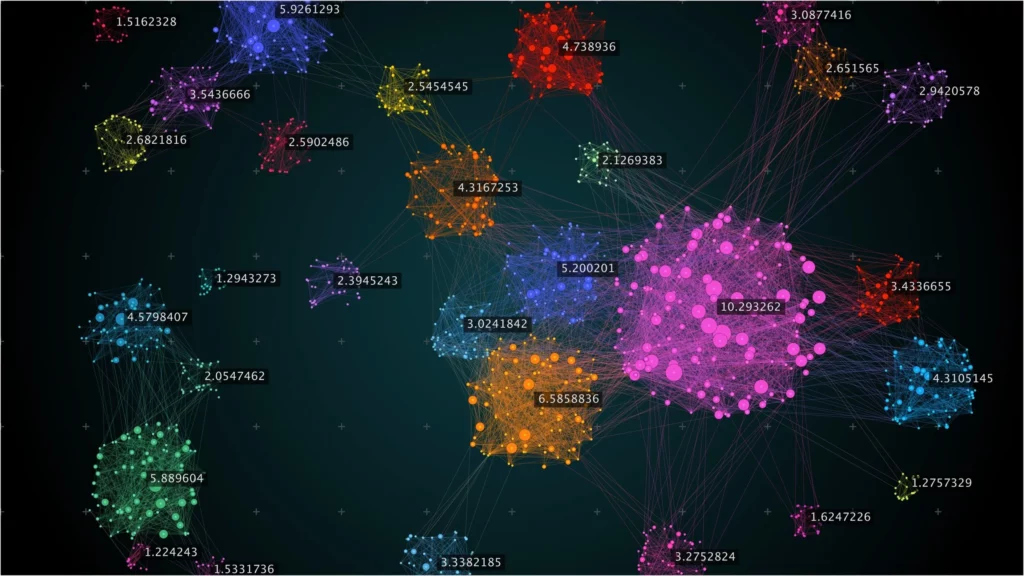
Clustering is basically: “Hey machine, there are loads of data points here; can you find groups that belong together?” For example,e: customer data might cluster into “frequent buyers”, “casual shoppers”, and “one-time visitors”. Popular methods include K-Means, hierarchical clustering, and DBSCAN.
Why you’d use it: if you want to segment your users or detect group behavior without predefined categories.
Dimensionality Reduction simplifying complexity
Then there’s dimensionality reduction: you have data with lots of features (maybe hundreds), and you want to reduce it to something manageable while keeping the important bits. Methods like PCA, t-SNE, and UMAP help here.
Metaphor: imagine you have a high-resolution photo (10000 pixels) and you want a meaningful thumbnail; you reduce without losing the story.
Anomaly/Outlier Detection: spotting the odd one out
Tag image: anomaly detection graph, unusual data point highlighted
Sometimes you just want to find data points that don’t behave like the other, the weird ones. Maybe fraud transactions, faulty sensors, network intrusions. Non-supervised models are perfect for that, because you don’t need examples of “bad behavior” ahead of time. You just say, “learn what normal looks like,” and then everything else gets flagged.
Association Rules finding co-occurrence patterns

Another category is association rule learning: for example, “people who buy bread also buy butter”. You’re mining for rules in large datasets. It’s unsupervised because you didn’t label the data; you’re discovering hidden relationships.
How the Workflow Looks for foNon-Superviseded Learning
If you’ve done supervised projects, you’ll recognise many steps,s unsupervised project adds its own flavor. Let’s walk through a typical process.
Step 1: Data collection & exploration
Just like supervised learning, you start with data gathering. But here you might not know what labels exist (or if they even exist). So you spend more time exploring: seeing distributions, missing data, features, and correlations.
Step 2: Data preprocessing & feature engineering
Clean data, handle missing values, normalise/standardise features, maybe do feature transformations. Since you don’t rely on labels to guide you, selecting good features is often more creative.
Step 3: Choosing the technique & model
You decide: do I want clusters? Do I want to reduce dimensions? Do I want anomaly detection? That decision depends on your business question and data quirks.
Step 4: Model training & validation
For clustering,, you might look at metrics like the silhouette score. dimensionality reduction, you look at explained variance. anomaly,,s ybe you manually inspect flagged ones. Because you don’t have labels, validation gets trickie, more art than science.
Step 5: Interpret results & deploy insights
Once model results are in, you interpret: “These are our clusters”, “These variables explain most of the variance”, “These transactions are anomalies”. Then you deploy: segmentation in marketing, anomaly alerts in monitoring, feature reduction in downstream pipelines.
Resource/Cost Estimate Table
| Phase | Key Activities | Estimated Duration | Estimated Cost* |
|---|---|---|---|
| Data collection & prep | Raw data gathering, cleaning | 2-8 weeks | USD 5,000 – 30,000 |
| Technique selection & modeling | Choosing an algorithm, running experiments | 2-6 weeks | USD 2,000 – 15,000 |
| Deployment & monitoring | Integrate model, monitor, refine | Ongoing | Monthly: USD 500 – 5,000 |
*These are very rough estimates; actual cost depends on data size, compute resources, and domain complexity.
Real-World Applications of Non-Supervised Machine Learning
Let’s jump out of theory and into where this stuff actually becomes useful, aka when your tech tool actually helps someone.
Customer segmentation and personalization
E-commerce companies don’t always know ahead of time how to segment customers. Using clusterin, they let data speak: “Oh hey, we’ve got a group that buys late at night with coupons, “another that browses but never buys” Then they tailor email campaigns or UX accordingly.
Anomaly detection in cybersecurity and operations
Networks, sensors, and logs produce tons of data. Supervised models might struggle because you don’t have labeled incidents for every scenario. Non-supervised methods help flag unusual patterns, potential intrusion, or faulty equipment.
Dimensionality reduction for visualization and feature engineering
Sometimes your model is too heavy because you have hundreds of features. Using unsupervised methods to reduce dimensions helps you visualise, compress, and feed lighter data into downstream supervised tasks. It’s like compressing your SAT vocabulary list before exam day.
Market basket & association rule insights
Retailers want to know: when people buy X, what else do they buy? Unsupervised rule mining helps find those hidden patterns without having predefined “if this then that” rules. It gives you golden nuggets for promotions.
Challenges, Limitations & Best Practices
Before you go full steam ahead into unsupervised modelling, let’s chat about the messy bits because yes, there are quite a few.
No labels means a harder evaluation.
The lack of ground truth labels means you often can’t say “yess this prediction is 95% correct”. You rely on internal metrics or human-in-the-loop evaluation. It’s a bit more art than mathematics.
Interpretability and actionable insights
Just because you found clusters doesn’t mean you know what they mean. Maybe you end up with groups that don’t make business sense. So you need domain knowledge. That’s the “experience” b.it
Risk of discovering spurious patterns
Without careful oversight, your model might find patterns that look real but are meaningless (coincidences). Be careful not to over-interpret. Always ask: Does this make sense in the real world?
Data quality and feature relevance matter a lot
Tag image: messy dataset illustration, missing value problem
If data is noisy, has missing values, or irrelevant features, unsupervised models may cluster poorly or reduce dimensions poorly. Investing in good data still holds.
Best practices to increase success
-
Spend time doing exploratory data analysis (EDA) to understand your data first.
-
Use domain expertise to interpret results.
-
Validate clusters or dimensions with business/ stakeholder input.
-
Use visualization to make sense of model findings.
-
Combine unsupervised with supervised in hybrid pipelines for stronger results.
-
Monitor and retrain: even without labels, track metrics and look for drift.
Practical Tips for Getting Started
Alright, you’re intrigued and maybe ready to experiment. Here are some practical tips to start on the right foot.
-
Begin with a small subset of data to understand patterns before scaling up.
-
Try simple algorithms first: K-Means, PCA, hierarchical clustering.
-
Visualise results early: scatter plots, dendrograms, and heatmaps help reveal patterns.
-
Use silhouette score (for clustering), explained variance (for PCA), or manual inspection (for anomalies) to evaluate.
-
Document your findings on what clusters mean, what dimensions represent.
-
Think about business value: what will you do with the clustering? If you can’t answer, maybe you need to be supervised instead.
-
Don’t ignore cleanup: good data still matters even though you don’t have labels.
-
Use interactive tools (Jupyter notebooks, visual dashboards) so you can play around and see insights fast.
Conclusion
Non-supervised machine learning opens a world of possibilities when you have lots of data but little to no labels. It’s like giving your machine a sandbox and saying, “Go play, find patterns, bring me back interesting stuff.” What you get may be clusters of behaviour, hidden anomalies, meaningful compressions of complex data, or rules you didn’t know existed.
Because there are no labels, this approach demands more creativity, more domain knowledge, and more care. You’re steering the ship, guiding the interpretation, asking the questions: “Does this cluster make sense?”, Are these anomalies real?, What can we do with these dimensions? This is where your expertise, your experience, and your trustworthiness matter.
In real-world settings, marketing segmentation, cybersecurity, feature engineering, retail insight,s nonon-superviseded machine learning deliver value when used wisely. But it’s not plug-and-play. The challenges exist: evaluation without labels, interpretation of results, risk of spurious patterns, and dependency on data quality.
If you’re in the tech world (you know who you are) and want to incorporate unsupervised learning into your toolkit, remember: start simple, visualise often, combine with domain insight, and keep the business question front-and-center. Because ultimately ,the model is only as valuable as the action it enables.
In short, when you employ non-supervised machine learning, you’re tapping into the machine’s ability to explore the unknown, discover the unseen, and give you insights where you had none. It’s a powerful tool, but like any powerful tool, it demands respect, proper handling, and human guidance.